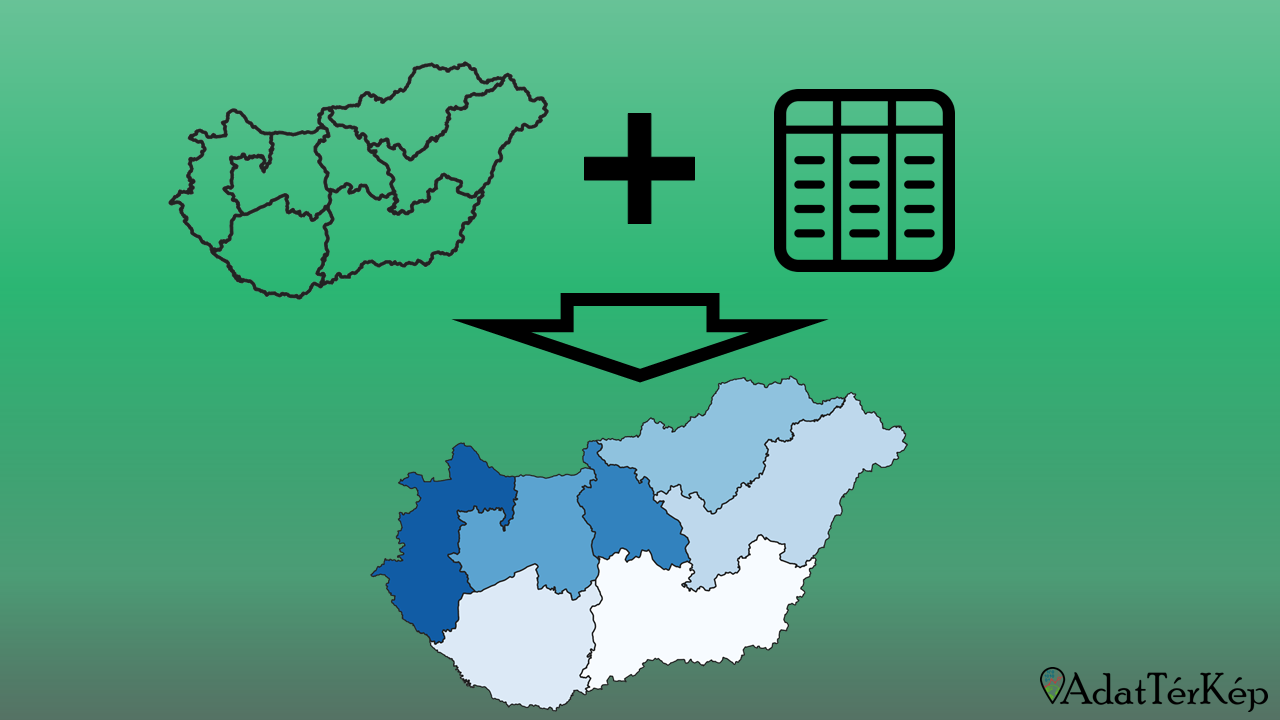
Társadalmi-gazdasági jelenségek (pl. demográfia) fajlagos mutatókkal leírható dimenzióinak (pl. népsűrűség) ábrázolására gyakran használjuk a tematikus térképet. A tematikus térképek készítéséhez egyrészt ismerni kell a rájuk vonatkozó módszertani szabályokat, másrészt a technológiai eszközkészletet, amelyeken keresztül a megfelelő módszertani szabályok érvényesíthetők. A tematikus térképkészítés sokszínű világával és ennek szabályrendszerével ezúttal nem foglalkozunk, egy későbbi bejegyzésünkben azonban erre is kitérünk majd. Ebben a bejegyzésben arra helyezem a hangsúlyt, hogyan lehet külső adatforrást használni a tematikus térképezés során, és milyen lépéseken keresztül jutunk el egy egyszerű felületkitöltéssel ábrázolt tematikus térképig.
Statisztikai adatok
Elsőként azonosítani kell azt a társadalmi-gazdasági jelenséget, illetve az ezt leíró adatokat, amelyeket szeretnénk tematikus térképen ábrázolni. Ha megtaláltuk vagy előállítottuk az adatokat, rendezzük őket táblázatos formába, pl. Excel segítségével. A kialakított táblázat csak egysoros fejlécet tartalmazzon, s minden sor egy vizsgálati egységet jelentsen. Ha egy településsoros vizsgálatot szeretnénk készíteni, akkor minden sorban egy és csak egy település adatai szerepeljenek. Fontos továbbá, hogy a táblázatban legyen legalább egy oszlop, amelynek tartalma alapján az egyes vizsgálati egységeket azonosítani lehet.
Nézzük meg mindezt egy példán keresztül! Tematikus térképen szeretnénk ábrázolni a magyarországi települések népsűrűségét, hogy lássuk, merre találhatók sűrűbben és ritkábban lakott települések az országban. A népsűrűség számításához ismernünk kell a település lakosságszámát és területét. Mindkét adat elérhető a Központi Statisztikai Hivatal által közzétett Helységnévtár adatbázisában. A honlapon lehet településenként keresni, illetve letölthető minden település adata egyben (.XLS formátumban) a felső menü Letöltés menüpontjára kattintva. A letöltött Excel fájl kétsoros fejlécet tartalmaz és számos olyan oszlopa van, amelyek adatai nem szükségesek a népsűrűség számításához, maga a népsűrűség azonban nem szerepel benne.

Ezért némi módosítást eszközölünk az adattáblán: kitöröljük a felesleges oszlopokat, egy új oszlopba pedig kiszámítjuk a népsűrűség értékét minden településre. A kétsoros fejlécet átalakítjuk egysorossá. Az így átalakított táblázat már alkalmas lesz külső adatforrásnak a tematikus térképünkhöz, hiszen azonosító oszlopokat is tartalmaz: megfelelő erre a célra a településnév és az ötjegyű KSH kód is.

Geometria adatok
Az alfanumerikus statisztikai adatokon túl szükség lesz egy, a vizsgálati egységek geometriáját és azonosítóit tartalmazó vektoros téradatra. Példánkat tovább folytatva: szükség lesz egy település polygon állományra (shapefile, geojson, geopackage, stb.), amelynek az attribútum táblájában szerepel egy olyan oszlop, amelynek tartalma alkalmas az egyes elemek azonosítására. Ehhez letöltjük az OpenStreetMap adataiból a településhatárt tartalmazókat (Magyarország esetében: admin_level = 8).
")
A letöltött adat nemcsak a települések polygonjainak geometriáját tartalmazza, hanem attribútum táblájában számos további információt is, pl. a települések nevét, amely alkalmas lehet a statisztikai adatokkal való összekapcsolásra.
Kapcsoló mező
Biztosan feltűnt, hogy mind a statisztikai, mind a geometriai adatoknál említettem, hogy szükség van legalább egy-egy azonosításra alkalmas oszlopra. Azt azonban még nem említettem, hogy ezek közül legalább egynek azonosnak kell lennie mindkét állományban. A mindkét adattáblában megjelenő azonosító oszlop szükséges ahhoz, hogy összekapcsolhassuk őket. Ha van rá mód, válasszunk valamilyen számszerű azonosító kódot, mert ezek esetében kisebb az elgépelésből és eltérő karakterkódolásból származó hibák lehetősége. Településeknél ez lehetne a Központi Statisztikai Hivatal által bevezetett KSH kód. A példánkban ez azonban csak az alfanumerikus adatok táblájában áll rendelkezésre, a polygon rétegben nincs ilyen. Ilyenkor (jobb híján) használható a vizsgálati egység köznapi elnevezése is, azonban fokozottan figyeljünk, és ha lehet, ellenőrzésekkel biztosítsuk a két oszlop tartalmának egységét. A példánkban így a településnevet használjuk majd a két adat összekapcsolására.
Adatok megnyitása
Most, hogy már minden adat rendelkezésre áll, nyissuk meg a QGIS-t! A vektoros téradatot adom hozzá elsőként, de ez nem kötelező, a sorrend egyelőre nem lényeges. Vektoros téradat megnyitásához használjuk a Layer menü, Add Layer, Add Vector Layer menüpontját és tallózzuk ki a .GEOJSON fájlt!

Következőként a statisztikai adatokat adom hozzá a projekthez, amelyeket előtte Excelben elmentettem .CSV formátumban, pontosvesszővel tagolva az értékeket. Válasszuk a Layer menü, Add Layer, Add Delimited Text Layer menüpontját és tallózzuk ki az imént mentett .CSV fájlt! A megnyitás során meg kell adni, mi a tagolókarakter, milyen karakter jelöli a szöveg kezdetét és végét, milyen karaktert használunk a tizedes tagolásra, stb. Rákérdez arra is, hogy a szövegfájlban van-e geometriát leíró információ: esetünkben ilyen nincs.

Ezen a ponton tehát a QGIS projetkthez hozzáadtuk a geometriát tartalmazó téradatot és az alfanumerikus adatokat tartalmazó CSV táblát is, s mindkettőben van egy oszlop (településnév), amely egyfelől egyedileg azonosítja a településeket, másfelől alkalmas e két adat összekapcsolására.
Mindkét réteg esetében ellenőrizzük, hogy a speciális karakterek (pl. ékezetes betűk) jól jelennek-e meg! Ehhez a vizsgálni kívánt rétegen jobb egérgombbal kattintsunk és válasszuk az Open Attribute Table menüpontot. Ha a megjelenő táblázatban jól jelennek meg az ékezetes karakterek, nincs teendő, ám ha fura karakterek látszanak az attribútum táblában, akkor ismét kattintsunk jobb egérgombbal a rétegre és válasszuk a Properties menüpontot. A megjelenő Layer Properties ablak Source fülén a Data Source Encoding értékét változtasd meg! Leggyakrabban a System és az UTF-8 beállítások vezetnek eredményre.
Adatok összekapcsolása
Mit értek az alatt, hogy a két állományt összekapcsolom? Jelen pillanatban a két réteg mást és mást tud. A téradat tudja, melyik település hol van, viszont sejtése sincs, mennyi az egyes települések népsűrűsége. Az alfanumerikus adat épp ezt tudja, viszont ezt az információt nem tudja térben elhelyezni. A tematikus térképhez azonban szükségem van mindkét információra, így az egyik állomány adattartalmával felokosítom a másikat: a .CSV-ből származó adatokkal szeretném kibővíteni a téradatréteg attribútum tábláját.
A kapcsolat létrehozásához a geometriai adat felől kell közelítenünk, ezért ennek a tulajdonságait jelenítjük meg (jobb egérgombbal kattintunk a rétegre, majd Properties menüpont). A Layer Properties ablak Join fülét kell kiválasztani, ami egyelőre nagyon üresnek tűnhet. Az ablak alján található zöld hozzáadás gombbal lehet egy új kapcsolatot létrehozni. A megjelenő ablakban 3 fontos beállítást kell megtennünk:
- ki kell választani, melyik adattáblát szeretnénk kapcsolni a geometriához (Join layer)
- ki kell választani, a csatolni kívánt táblában melyik oszlop tartalmazza a kapcsoláshoz használni kívánt azonosítókat (Join field)
- ki kell választani, az aktuális téradat réteg melyik attribútuma tartalmazza a kapcsoláshoz használni kívánt azonosítókat (Target field)

A fenti 3 információ megadásán túl számos további paramétert is megadhatunk, én ebből most csak az előtagot emelném ki. Alapértelmezetten a .CSV fájlból készített adatréteg nevét (a példánkban "helysegnevtar_" az oszlopnév elé fűzve alakítja ki a kapcsolatnak köszönhetően megjelenő oszlopok elnevezését (pl. "helysegnevtar_nepsuruseg"), hogy elkerülje az oszlopnevek duplikálásából fakadó hibákat. (Egy attribútum táblában minden oszlopnak egyedi névvel kell szerepelnie.) A CSV-ből képzett réteg neve azonban sokszor nagyon hosszú, így a program lehetőséget kínál arra, hogy ezt az előtagot (prefix-et), megváltoztassuk. Ehhez a Custom field name prefix jelölőnégyzetet ki kell pipálni és az alatta lévő beviteli mezőbe be kell írni a használni kívánt előtagot (pl. "hnt_"). Így a téradat (a telepules nevű réteg) attribútum táblájában megjelenő új oszlopok neve "hnt_"-vel kezdődik (pl. "hnt_nepsuruseg").

Ábrázolási mód kiválasztása
Az eddig leírtakra csak akkor van szükség, ha a tematikus térképezéshez szükséges alfanumerikus adatokat külső forrásból használjuk, s nem szerepelnek eleve a téradatunk attribútum táblájában. Mostanra már mindenképp ez a helyzet, így elérhetővé válnak adatvezérelt megjelenítési lehetőségek. Az előző lépésekben “felokosított” réteg (telepules réteg) tulajdonságai (jobb-klikk, Properties) közül a Symbology fület kell választani, azon belül pedig felül a legördülő menüből a Graduated menüpontot.

Valamivel lejjebb ki kell választani egy színskálát (Color ramp), amelyről a QGIS színeket választhat majd az egyes osztásközök megjelenítésére.

Osztályozás beállítása
A folytonos skálán mért számszerű értékek esetében ritkán szeretnénk minden egyes értéket eltérő jelöléssel megjeleníteni. Inkább bizonyos logika mentén egyszerűsítve, csoportosítva szoktuk kezelni őket, pl. alacssony - átlag körüli - magas értékek bontásában. Ezt a csoportosítást nevezzük tematikus térképek esetében osztályozásnak. A QGIS segít az osztályok kialakításában, de néhány kérdést feltesz számunkra. Az első az, hogy hány részre szeretnénk darabolni az adatsort. A második pedig az, hogy milyen logika mentén szeretnénk a felosztást elvégezni.

A QGIS több osztályozási logikát is felkínál, amelyekből most csak néhányat emelek ki és ismertetek:
- Equal Interval (egyenlő osztásköz): Megvizsgálja az adatsor minimum és maximum értékét és a kettő különbségét (a terjedelmet) annyi egyforma részre bontja, ahány osztállyal dolgozni szeretnénk. Így bármelyik osztály felső és alsó értékének különbsége egyenlő lesz, innen ered az osztályozási módszer neve is.
- Quantile / Equal Count (egyenlő elemszám): Úgy alakítja ki a kívánt számú osztályt, hogy mindegyikbe (a lehetőségekhez mérten) egyelő számú vizsgálati egység kerüljön.
- Natural Breaks / Jenks (természetes törés): Megvizsgálja az adatsor leíró statisztikáját és ott próbál osztályhatárokat elhelyezi, ahol az adatsorban amúgy is találhatók “törések”, vagyis nagyobb számosságbeli eltérések.
- Egyéni: Nincs erre külön opció. Az egyes osztályok alsó és felső értéke akár eredetileg is megadható, akár módosítható a felhasználó igényei szerint.
Mindegyik osztályozási logikának vannak előnyei és hátrányai, s mindegyik torzító hatással van a jelenség értelmezésére, mivel mindegyik egyszerűsít, összevon, mást és mást emel ki, illetve fed el. Személyes gyakorlatomban szinte sosem használom önállóan egyik előredefiniált osztályozást sem. Általában kiválasztom a fent leírt logikát, majd az osztályok alsó és felső értékeit módosítom úgy, hogy “kerekebb”, emberi szem számára könnyebben értelmezhető értékeket vegyenek fel.


Az eredmény egy külső adatforrást használó tematikus térkép. A későbbi feladatok függvényében még cizellálható a tematikus térkép beállítása, vagy elmenthető a téradat olyan módon, hogy már része legyen a külső adatforrás adattartalma is, vagy összeállítható egy címmel, jelmagyarázattal, mértékléccel, stb. ellátott, nyomtatáskész ábra, vagy ... rengeteg további lehetőség áll még rendelkezésünkre, amelyekről még későbbi bejegyzéseinkben olvashattok részletesebben!
A tematikus térkép készítéséhez használt adatok letölthetők a GitHub oldalunkról!